nodejs unicode

1. Intro
기본적인 ASCII 범위를 벗어나 전세계 언어를 표현하기 위해 unicode를 많이 사용합니다. 이로 인해 ASCII로 표현이 불가능 했던 문자를 unicode로 표현이 가능해졌습니다.
이로 인해 예상치 못한 버그가 발생하곤 합니다. 이에 대해 설명하고자 합니다.
2. Compare unicode
사용자는 unicode를 통해 다양한 문자를 입력할 수 있습니다. 서버는 사용자가 입력한 값을 처리하는 과정을 거치겠죠.
예를들어, 사용자가 unicode K 를 입력했다고 가정합시다. 이 값과 ASCII 에서 소문자 k 와 비교하면 당연히 `false`가 출력 되겠죠.
"K" == "k"
false
하지만, unicode K를 toLowerCase() 함수를 이용하여 소문자로 바꾼 뒤, ASCII 소문자 k 와 비교하면 놀랍게도 `true` 라는 값이 리턴됩니다.
"K".toLowerCase() == "k"
trueJavascript 뿐만 아니라 다른 언어에서도 동일한 현상이 발생됩니다. (여기서 \u212 는 unicode K 입니다.)
즉, unicode K 는 소문자로 바꿔서 비교할 때, 보안적인 관점에서는 위험한 로직임을 알 수 있습니다.

소문자말고 대문자로 변환할 때도 위와 같은 현상이 발생합니다.
그 예로 아래와 같이 코드를 실행하면 두 문자가 같다는 결과를 얻을 수 있습니다.
'ff'.toUpperCase() == "FF"
true
3. url.parse
nodejs 에서 url 모듈은 전달된 url 을 파싱하는 모듈 입니다. 만약 host에 위와 같은 unicode 넣게 되면 어떤 일이 발생하게 될까요?
`url.parse()` 함수를 통해 unicode K 값을 host에 전달하면 다음과 같은 결과를 얻을 수 있습니다.
`url.parse()` 함수에서 host 부분은 자동으로 unicode normalization을 하게 됩니다.
const url = require("url");
url.parse("http://test\u212a.com")
/*
result
Url {
protocol: 'http:',
slashes: true,
auth: null,
host: 'testk.com',
port: null,
hostname: 'testk.com',
hash: null,
search: null,
query: null,
pathname: '/',
path: '/',
href: 'http://testk.com/'
}
*/
url.parse("http://test\u212a.com").host == "testk.com"
// true
url.parse("http://test\u212a.com").href == "http://testk.com/"
// true
실제로 url.parse() 함수의 소스 코드를 보면 `punycode.toASCII()` 함수를 통해 non-ascii 문자를 ascii로 변환해주는 작업을 하고 있습니다. 이 host 값은 href 값에도 사용되고 있습니다.
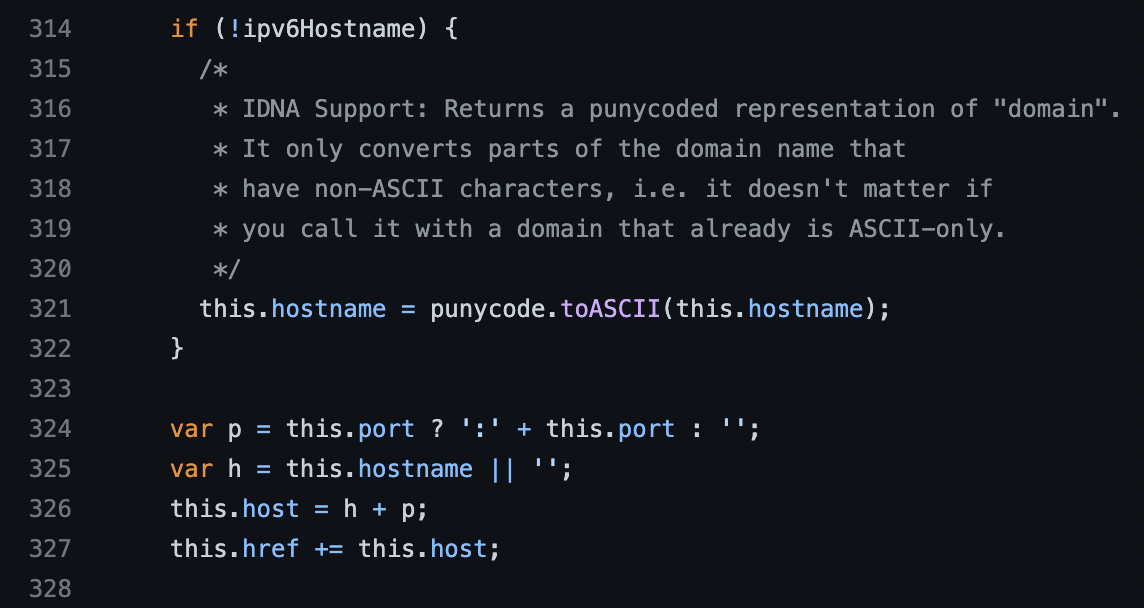
`punycode.toASCII()` 함수를 통해 non-ascii 문자를 ascii로 변환하고 있지만, 이를 다음과 같이 악용할 수 있습니다.
ASCII 문자인 @를 넣게 되면, url.parse() 함수를 통해 당연히 @ 뒤에 있는 것을 host로 파싱하게 됩니다.
url.parse("http://naver.com@attacker.com")
Url {
protocol: 'http:',
slashes: true,
auth: 'naver.com',
host: 'attacker.com',
port: null,
hostname: 'attacker.com',
hash: null,
search: null,
query: null,
pathname: '/',
path: '/',
href: 'http://naver.com@attacker.com/'
}
하지만, ASCII 문자 @가 아닌 unicode ﹫를 넣게 되면, 위의 host 결과와는 다른 결과가 출력됩니다.
url.parse("http://naver.com﹫attacker.com")
Url {
protocol: 'http:',
slashes: true,
auth: null,
host: 'naver.com@attacker.com',
port: null,
hostname: 'naver.com@attacker.com',
hash: null,
search: null,
query: null,
pathname: '/',
path: '/',
href: 'http://naver.com@attacker.com/'
}
만약, 어떤 웹 서비스에서 `url.parse('http://naver.com﹫attacker.com').host.indexOf("naver.com") != -1` 로 검증하게 되면 host 검증을 bypass 할 수 있게 됩니다.
unicode ﹫ 말고도 `;` , `/` , `#` 등을 이용하여 parse 구분 분석을 우회하여 요청할 url을 조작할 수 있습니다.
4. Reference
https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html
https://appcheck-ng.com/wp-content/uploads/unicode_normalization.html
` 0x60 `%e1%bf%af`NFKD,NFKC,NFD,NFC `%ef%bd%80`NFKD,NFKC
appcheck-ng.com
https://gosecure.github.io/unicode-pentester-cheatsheet/
Characters that byͥte
gosecure.github.io
'🔒Security' 카테고리의 다른 글
| ctf 문제를 통해 CSP bypass 정리하기 (0) | 2023.03.13 |
|---|---|
| SSRF bypass using DNS Rebinding (0) | 2023.01.04 |
| [분석일기] - php switch case (0) | 2022.09.06 |
| [분석 일기] - EJS, Server Side Template Injection to RCE (CVE-2022-29078) (6) | 2022.07.21 |
| Node.js querystring 함수 분석과 bug 설명 (0) | 2022.07.09 |