[python] - beautiful soup를 이용한 웹 크롤러 만들기

Web Crawler 란?
정식 명칭은 Web scraping 이라고 불리며, 이는 웹 사이트에서 원하는 정보를 추출하는 것을 말한다.
웹 사이트에 방문헤서 자료를 수집하고, 하나의 페이지 뿐만 아니라 그 페이지에 링크되어 있는 것도 방문하여 정보를 수집한다.
필자는 python 을 이용하여 간단한 web scraping을 만들어 볼 것이다.
Web Crawler를 만들기 전에
필자는 모듈을 2가지를 쓸 건데, requtests 와 bs4 라는 모듈을 사용할 것이다.
- pip install requests
- pip install bs4
requests 모듈에 대한 간단한 설명은 아래 포스트를 참고하면 도움이 될 것이다.
Web Crawler 만들기
본격적으로 python으로 web scraping을 만들어 보자.
예시로 사용할 사이트는 보안뉴스의 기사이다. https://www.boannews.com/media/t_list.asp

위 링크에 들어가면 위 사진처럼 보안 관련 기사를 볼 수 있다.
기사의 제목과 기사의 링크를 가져오는 것을 목표로 스크랩핑을 만들어 볼 것이다.
다음과 같이 코드를 짠 뒤에 실행하면 아래 사진 처럼 인터넷 기사들 중 맨 첫번째 기사를 볼 수 있다.
import requests
import bs4
# 해당 주소로 요쳥을 보낸 후 정보를 req 변수에 저장한다.
req = requests.get('https://www.boannews.com/media/t_list.asp')
# req에 들어있는 html 코드를 보기 위해서는
# req.text 로 볼 수 있다.
print(req.text)
이제 req.text 에 들어있는 값들에서 기사의 제목만 가져와 보겠다.
bs4를 이용하여 원하는 부분을 쉽게 찾기 위해서 아래 코드처럼 작성한다.
import requests
import bs4
# 해당 주소로 요쳥을 보낸 후 정보를 req 변수에 저장한다.
req = requests.get('https://www.boannews.com/media/t_list.asp')
# 원하는 부분을 쉽게 찾기 위해 bs4를 이용한다.
parse = bs4.BeautifulSoup(req.text, 'html.parser')
필자의 목표는 기사의 제목을 가져오는 것이기 때문에, 크롬에서 F12(개발자 모드)로 들어간뒤 기사 부분을 찾으면 <div id=’news_area’> ~~~ </div> 가 이 페이지의 모든 기사를 포함하고 있다라는 것을 볼 수 있다.
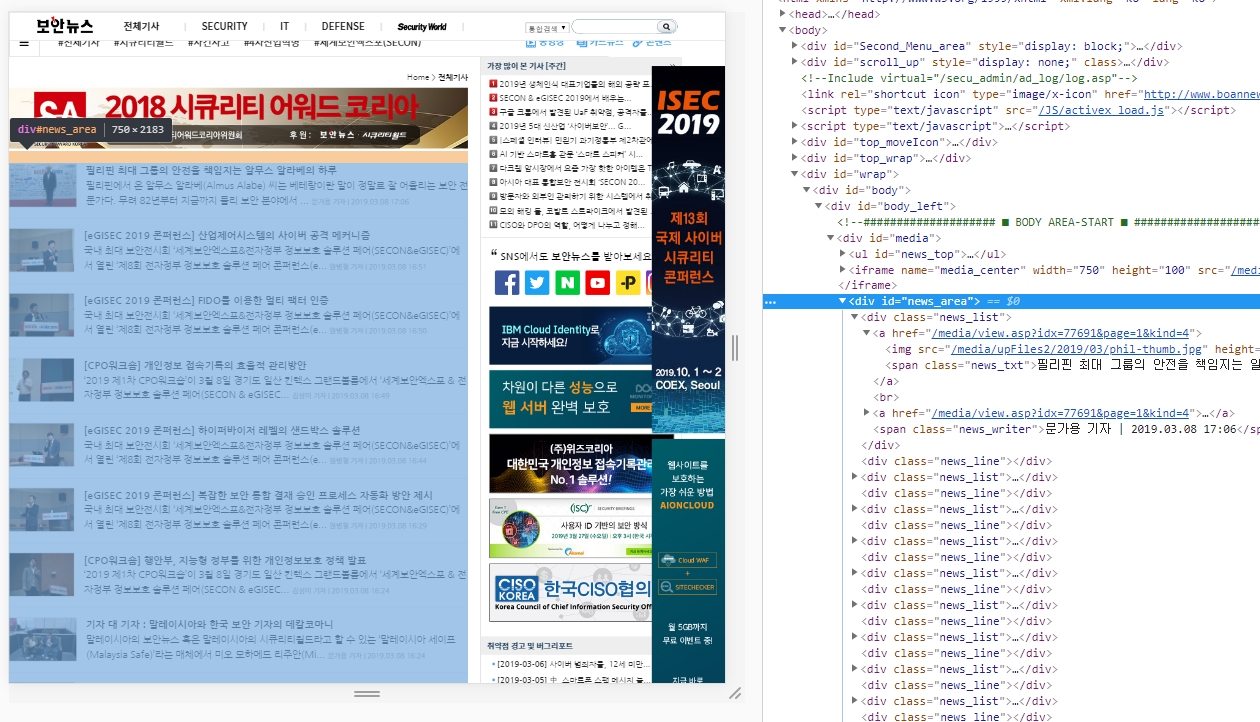
우리는 현재 <div id=’news_area’> ~~~ </div> 라는 곳에 모든 기사를 포함하고 있다라는 것을 알고 있으므로, 코드를 다음과 같이 적는다.
import requests
import bs4
# 해당 주소로 요쳥을 보낸 후 정보를 req 변수에 저장한다.
req = requests.get('https://www.boannews.com/media/t_list.asp')
# 원하는 부분을 쉽게 찾기 위해 bs4를 이용한다.
parse = bs4.BeautifulSoup(req.text, 'html.parser')
# <div id='news_area'> 부분에 기사가 있으므로 다음과 같이 코드를 작성한다.
newspaper = parse.find('div', {'id' : 'news_area'})
print(newspaper)위 코드에서 newspaper = parse.find(‘div’, {‘id’ : ‘news_area’}) 이 부분이 중요한데,
‘div‘ 는 찾을 html 태그 이름
{‘id’:’news_area’}는 id가 news_area인 것을 찾아서 newspaper라는 변수에 저장한다.
실행하면 아래 사진처럼 아까 전 보다는 필요한 부분만 가져 온 것을 볼 수 있다.

아직까지는 기사 제목만 가져오지는 못했다.
조금 더 걸러내면 기사 제목만 가져 올 수 있다.
아래 사진을 보면 <div id=’news_area’> ~~~ </div>안에 <div class=’news_list’> ~~ </div> 부분이 하나의 기사 내용을 담고 있는 것을 볼 수 있다.
<div class=’news_list’> ~~ </div> 부분이 여러개 있다는 것도 알 수 있다.
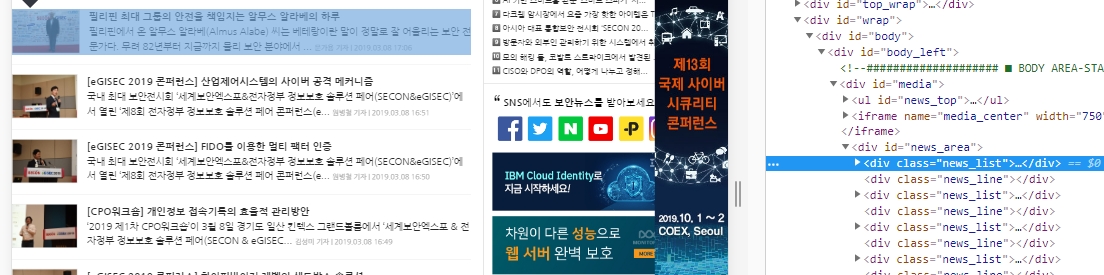
<div class=’news_list’> ~~ </div> 라는 html 코드가 여러개 있기 때문에 find() 라는 함수를 쓰면 하나의 <div class=’news_list’> ~~ </div> 만 가져오게 된다.
실제로 테스트를 해보면 아래와 같은 결과를 가져온다.
import requests
import bs4
# 해당 주소로 요쳥을 보낸 후 정보를 req 변수에 저장한다.
req = requests.get('https://www.boannews.com/media/t_list.asp')
# 원하는 부분을 쉽게 찾기 위해 bs4를 이용한다.
parse = bs4.BeautifulSoup(req.text, 'html.parser')
# <div id='news_area'> 부분에 기사가 있으므로 다음과 같이 코드를 작성한다.
newspaper = parse.find('div', {'id' : 'news_area'})
# <div class='news_list'> ~~ </div> 하나의 기사가 들어있는 부분이다.
newspaper = newspaper.find('div', {'class' : 'news_list'})
print(newspaper)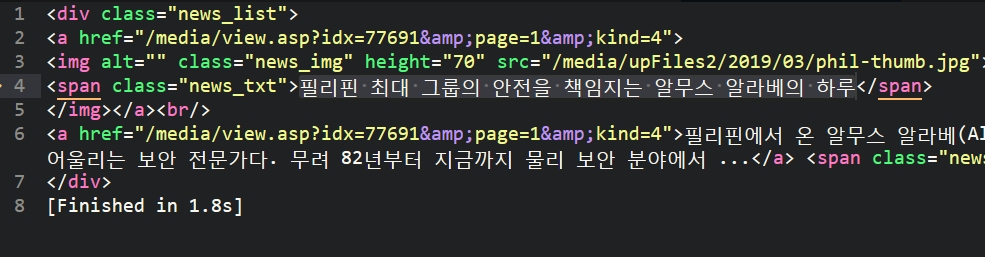
여러개의 html 태그를 가져오는 방법은 find_all() 함수를 사용하는 것이다.
find() 와 find_all()의 차이점을 설명하면 아래와 같다.
| find() | 찾고자 하는 html 태그를 찾게 되면 문자열 타입으로 리턴한다. 단, 2개 이상의 똑같은 html 태그가 있을 경우 맨 앞의 것만 리턴하고 나머지는 무시한다. |
| find_all() | 찾고자 하는 html 태그를 찾게 되면 list 타입으로 리턴한다. 만약 2개 이상의 똑같은 html 태그가 있다면 모두 찾은 뒤에 list 타입으로 리턴한다. |
| 공통점 | variable.find() 함수나 variable.find_all() 함수를 쓸때, variable 변수는 문자열이어야만 한다. |
필자가 이해한 대로 작성했지만, 이해가 되질 않는다면 직접 코드로 해보면 이해가 금방 갈것이다.
본론으로 돌아와서, 똑같은 html 태그를 가져오는 find_all() 함수를 쓰면 아래 사진 처럼 기사 부분을 가져오게 된다.
import requests
import bs4
# 해당 주소로 요쳥을 보낸 후 정보를 req 변수에 저장한다.
req = requests.get('https://www.boannews.com/media/t_list.asp')
# 원하는 부분을 쉽게 찾기 위해 bs4를 이용한다.
parse = bs4.BeautifulSoup(req.text, 'html.parser')
# <div id='news_area'> 부분에 기사가 있으므로 다음과 같이 코드를 작성한다.
newspaper = parse.find('div', {'id' : 'news_area'})
# <div class='news_list'> ~~ </div> 하나의 기사가 들어있는 부분이다.
newspaper = newspaper.find_all('div', {'class' : 'news_list'})
print(newspaper)
위 사진을 보면 기사 제목의 앞 부분에 <span class=’news_txt’> 라고 적혀있는 것을 볼 수 있다.
여기까지 잘 따라 왔으면 어떻게 코딩해야 할지를 알고 있을 것이다.
import requests
import bs4
# 해당 주소로 요쳥을 보낸 후 정보를 req 변수에 저장한다.
req = requests.get('https://www.boannews.com/media/t_list.asp')
# 원하는 부분을 쉽게 찾기 위해 bs4를 이용한다.
parse = bs4.BeautifulSoup(req.text, 'html.parser')
# <div id='news_area'> 부분에 기사가 있으므로 다음과 같이 코드를 작성한다.
newspaper = parse.find('div', {'id' : 'news_area'})
# <div class='news_list'> ~~ </div> 하나의 기사가 들어있는 부분이다.들어있는
newspaper = newspaper.find_all('div', {'class' : 'news_list'})
# <span class='news_text'> ~~ </span> 부분에 우리가 찾던 기사의 제목이 들어있다.!
# newspaper 변수는 문자열 타입이 아니라 list 타입 이므로 for 문으로 하나씩 찾아보자
for string in newspaper:
newsTitle = string.find('span',{'class':'news_txt'})
print(newsTitle)
이제 기사 부분만 가져 왔다. 하지만 html 태그가 들어 있으므로 text 부분만 가져와 보자.
text 부분만 가져오는 방법은 18번째 줄 마지막에 .text 부분을 붙여주면 된다.
import requests
import bs4
# 해당 주소로 요쳥을 보낸 후 정보를 req 변수에 저장한다.
req = requests.get('https://www.boannews.com/media/t_list.asp')
# 원하는 부분을 쉽게 찾기 위해 bs4를 이용한다.
parse = bs4.BeautifulSoup(req.text, 'html.parser')
# <div id='news_area'> 부분에 기사가 있으므로 다음과 같이 코드를 작성한다.
newspaper = parse.find('div', {'id' : 'news_area'})
# <div class='news_list'> ~~ </div> 하나의 기사가 들어있는 부분이다.들어있는
newspaper = newspaper.find_all('div', {'class' : 'news_list'})
# <span class='news_text'> ~~ </span> 부분에 우리가 찾던 기사의 제목이 들어있다.!
# newspaper 변수는 문자열 타입이 아니라 list 타입 이므로 for 문으로 하나씩 찾아보자
for string in newspaper:
# 수정된 부분 = 18번째줄 마지막에 .text를 붙인다.
newsTitle = string.find('span',{'class':'news_txt'}).text
print(newsTitle)
최종적으로 기사의 제목만 가져왔다.
이제 추가적으로 웹 서버를 구축해서 웹 스크래핑에서 가져온 기사 제목을 DB에 저장하여 쓴다거나, telegram 앱을 이용하여 몇분 간격으로 유저에게 뉴스 기사의 제목을 보낸다거나 등등의 이용 방법이 무궁무진하다.
'Code' 카테고리의 다른 글
| [jquery] - 카테고리 펼치기 접기 만들기 (2) | 2019.10.12 |
|---|---|
| [web] - javascript로 unix timestamp 변환하기 (0) | 2019.08.07 |
| [python] - requests 모듈을 이용한 웹 요청 (0) | 2019.04.06 |
| [python] – sha256 암호화 및 복호화 (0) | 2019.04.06 |
| [python] – md5 암호화 및 복호화 (0) | 2019.04.06 |